興味本位で始めた、機械学習用不倫データセットと、Pythonの機械学習ライブラリscikit-learnを使って、愛妻の不倫を予測した前回の続き。(疑っているわけじゃないです)
結局、どのパラメータが不倫の大きな要因なのか? 不倫を避けるにはどうすればいいのか?
と疑問に感じた人が調べるのは、係数(coefficient)です。
詳しい話はUdemyの実践 Python データサイエンスの講習やWikipediaを参照するとして、ざっくり言うと、「旦那の職業」「妻本人の職業」「子供の人数」・・・などの係数のうち、どれが目的変数(妻が不倫するかしないか)を決定するのに最も影響力を持つか、と解釈しました。
係数は、前回作ったロジスティック回帰modelに格納されているので、一目でわかるように可視化します。
from sklearn.linear_model import LogisticRegression
from sklearn.cross_validation import train_test_split
# トレーニング用データと確認用データを分離
X_train, X_test, Y_train, Y_test = train_test_split(X, Y, train_size=0.9)
# モデルを作成
model = LogisticRegression()
model.fit(X_train, Y_train)
# 係数を可視化するためにDataFrame化
coef = DataFrame(model.coef_[0])
coef.columns = ["value"]
# X軸のラベルと合わせてグラフ描画、画像ファイルに保存
plt.plot("value", data=coef)
plt.xticks(coef.index, X.columns, rotation=90)
plt.savefig("coef.png")
その結果がこれ。
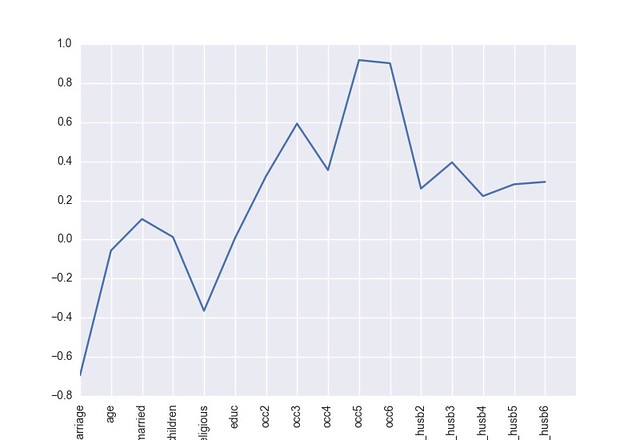
見てみると、以下の5つが不倫させる係数上位5つ。
- 妻本人の職業: managerial, administrative, business (経営管理者)
- 妻本人の職業: professional with advanced degree (上位学位を持った専門職)
- 妻本人の職業: white-colloar (ホワイトカラー労働者のこと?)
- 旦那の職業: white-colloar (ホワイトカラー労働者のこと?)
- 妻本人の職業: teacher counselor social worker? 看護師、アーティスト、ライター・・・って幅広すぎ
逆に、不倫させない係数は以下の5つ。
- rate marriage: ~~結婚式の値段?~~ 結婚に対する満足度
- religious: 信心深さ
- age: 年齢
- children: 子供の人数
- yrs_married: 結婚生活の年数
~~Rate marriageの訳は、これで合ってるのかな・・・?~~ @dgakane さんに訂正いただきました。あざっす!
不倫させない係数はともかく、不倫させる係数は全て職業絡みってのが興味深いですね。No.5に含まれる職業の幅が広過ぎるのが若干気になりますが・・・。
ただ、これが職業のせいなのか、職業による仕事への拘束時間のせいなのか、ちょっと判断しづらい気もします。
職業からくるパラメータをもっと細分化して、労働時間とか帰宅時間とか、旦那が子育てに費やす時間とかのパラメータがあると、さらに面白いかもですね。
==※:念のため注意。この記事に書いてある不倫の要因とか、ただのネタなので信用しないでくださいね。==
