実践Pythonデータサイエンスのレクチャー86 決定木とランダムフォレスト、やっっっと最終章に辿り着きました。
まぁ、理解しきれてないけど… 長かった。
この最終章、visualize_tree()という独自関数を使ってランダムフォレスト分類器による分類結果を二次元マップとして描いて可視化するんですが、パッと見、よく分からないんです。
理解した気になったmeshgrid()関数のことを、実際は理解できていなかったことも要因かな…。
復習を兼ねてvisualize_tree()関数を紐解いてみたら、その過程がとても楽しかったので、簡単に紹介します。
やりたいこと
機械学習の教師用データを自分で作り、それを学習したモデルを作って、未知のデータを網羅的に与えた結果を図示して楽しむのが、ここでの目的です。
機械学習って、本来はもっと高尚な目的があって分析すると思うんですが、ここではその辺りは無視します。
可視化までの流れ概略
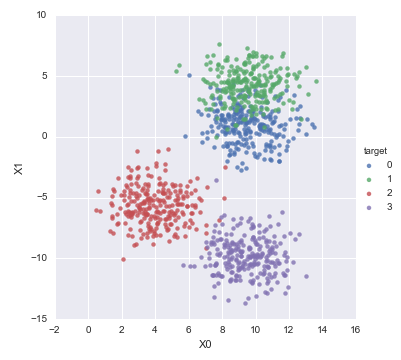
教師用データを単純に描画するとこうなって、
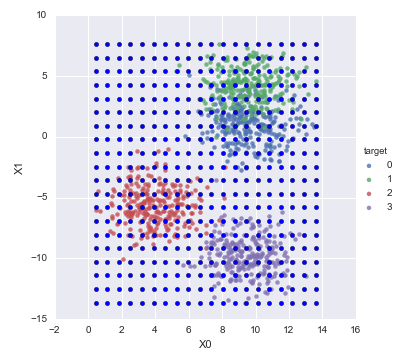
教師用データの最大最小範囲に収まる領域を満遍なく予測するため、青い点で示した座標値を作り、
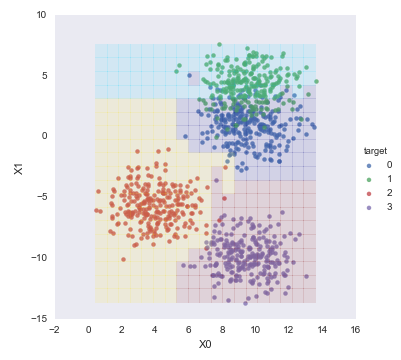
それを分類モデルに与えて、結果を色付けして重ねてやると、こうなる。これは面白い。
可視化までの流れ詳細
では、実際にコードを書いて備忘録を作っていきます。
教師となるデータを作る
まずはsklearn.datasets.make_blobs関数を使って、教師データを作ります。
import numpy as np
import pandas as pd
from pandas import DataFrame, Series
from sklearn.datasets import make_blobs
import seaborn as sns
X, y = make_blobs(
n_samples=1000, # サンプル数
n_features=2, # 各サンプルの説明変数の数
centers=4, # 離散データのグループ数
cluster_std=1.5, # 離散データのバラけ具合
random_state=4) # 呼ぶたびにseedを変えずに固定
すると、各々のXに対する目的変数yが得られるようなデータが生成されます。
ちょっと中身を確認。
In[242]:len(X), len(y)
Out[242]:1000, 1000
In[243]:X
Out[243]:array([[ 8.34658867, -10.31879835],
[ 8.53921758, 5.79103131],
[ 9.28263663, 4.70668557],
...,
[ 9.98784011, -8.66323273],
[ 9.7863086 , -0.49802022],
[ 8.5105375 , 1.74524764]])
In[244]:y
Out[244]:array([3, 1, 1, 3, 1, 3, 1, 1, 0, 1, 1, 2, 1, 2, 0, 0, 1, 2, 3, 1, 1, 2, 3,
1, 2, 1, 0, 1, 2, 2, 0, 1, 1, 1, 2, 2, 3, 2, 2, 2, 0, 2, 3, 1, 2, 0,...
X[:,0]を横軸、X[:,1]を縦軸にして、yで色分けしつつ散布図にプロットすると、データの傾向がわかります。
make_blobsに与える引数cluster_stdやcentersを変えてみて、散布図がどう変化するか試すのも面白いです。
df = pd.concat(
[
DataFrame(X, columns=["X0","X1"]),
DataFrame(y, columns=["target",])
], axis=1)
sns.lmplot("X0","X1",data=df,hue="target",fit_reg=False)
教師データの最大最小範囲を網羅したデータを作る
さっき作ったのは教師データなので、機械学習モデルが正解パターンとして使うものでした。
今度は実際に分類したいデータを作ります。
教師データの最大最小に収まる範囲内を満遍なく分類したいので、下図の青い点のような座標値を作ります。
もっと細かく分割してもいいんですけど、散布図が見やすいようにこれくらいで。
まずは、教師用データのXの0番目要素全て(散布図の横軸)と1番目要素全て(散布図の縦軸)を取り出して、最大最小を割り出します。
要するに、上の図の青い点の四辺ですね。
x0_lim = X[:,0].min(), X[:,0].max()
x1_lim = X[:,1].min(), X[:,1].max()
縦横それぞれ20分割して、meshgrid関数に渡します。
x0, x1 = np.meshgrid(
np.linspace(*x0_lim, 20),
np.linspace(*x1_lim, 20))
meshgridの戻り値を見てみると分かりますが、
In [79]: x0_lim
Out[79]: (0.45642813876023558, 13.585891473268598)
In[244]:x0.shape
Out[244]:(20, 20)
In[245]:x0
Out[245]:
array([[0.45642814, 1.14745252, ..., 13.58589147],
[0.45642814, 1.14745252, ..., 13.58589147],
...,
[0.45642814, 1.14745252, ..., 13.58589147]])
In [81]: x1_lim
Out[81]: (-13.62745125180961, 7.6188184836933468)
In[246]:x1.shape
Out[246]:(20, 20)
In[247]:x1
Out[247]:
array([[-13.62745125, -13.62745125, ..., -13.62745125],
[-12.50922653, -12.50922653, ..., -12.50922653],
...,
[7.61881848, 7.61881848, ..., 7.61881848]])
x0の各成分を横軸座標、x1の各成分を縦軸座標とした配列、つまり以下のようなデータを作ってやれば、上の図の青い点の座標になります。
array([[(0.45642814, -13.62745125), (1.14745252, -13.62745125), ..., (13.58589147, -13.62745125)],
[(0.45642814, -12.50922653), (1.14745252, -12.50922653), ..., (13.58589147 -12.50922653),],
...,
[(0.45642814, 7.61881848), (1.14745252, 7.61881848), ..., (13.58589147, 7.61881848)]])
これを作るため、まずはnp.ndarrayのravelメソッドを使い、x0とx1それぞれの配列内の全要素をフラットに並べてしまいます。
In[85]:x0_ = x0.ravel()
In[86]:x1_ = x1.ravel()
In [87]: len(x0_)
Out[87]: 400
In [88]: x0_
Out[88]:
array([ 0.45642814, 1.14745252, 1.83847691, 2.5295013 , 3.22052568, 3.91155007, 4.60257445, 5.29359884, 5.98462323, 6.67564761, ... , 13.58589147, 0.45642814, 1.14745252, ...
x0_を横軸成分、x1_を縦軸成分とした座標となるような配列にしてやれば、
x01 = np.c_[x0_, x1_]
散布図の縦横20分割、計400座標の配列が出来上がり。
In[245]:x01.shape
Out[245]:(400, 2)
In[246]:x01
Out[246]:
array([[ 0.45642814, -13.62745125],
[ 1.14745252, -13.62745125],
[ 1.83847691, -13.62745125],
[ 2.5295013 , -13.62745125],
[ 3.22052568, -13.62745125],
[ 3.91155007, -13.62745125],
[ 4.60257445, -13.62745125],
[ 5.29359884, -13.62745125],
[ 5.98462323, -13.62745125],
[ 6.67564761, -13.62745125],
...
[ 7.366672 , 7.61881848],
[ 8.05769639, 7.61881848],
[ 8.74872077, 7.61881848],
[ 9.43974516, 7.61881848],
[ 10.13076954, 7.61881848],
[ 10.82179393, 7.61881848],
[ 11.51281832, 7.61881848],
[ 12.2038427 , 7.61881848],
[ 12.89486709, 7.61881848],
[ 13.58589147, 7.61881848]])
以下のようにすると、x0_lim, x1_lim, x01の関係性が分かりますね。
In [53]: x01[:,0].min(), x01[:,0].max()
Out[53]: (0.45642813876023558, 13.585891473268598)
In [55]: x0_lim
Out[55]: (0.45642813876023558, 13.585891473268598)
In [60]: x0_lim == (x01[:,0].min(), x01[:,0].max())
Out[60]: True
In [54]: x01[:,1].min(), x01[:,1].max()
Out[54]: (-13.62745125180961, 7.6188184836933468)
In [56]: x1_lim
Out[56]: (-13.62745125180961, 7.6188184836933468)
In [61]: x1_lim == (x01[:,1].min(), x01[:,1].max())
Out[61]: True
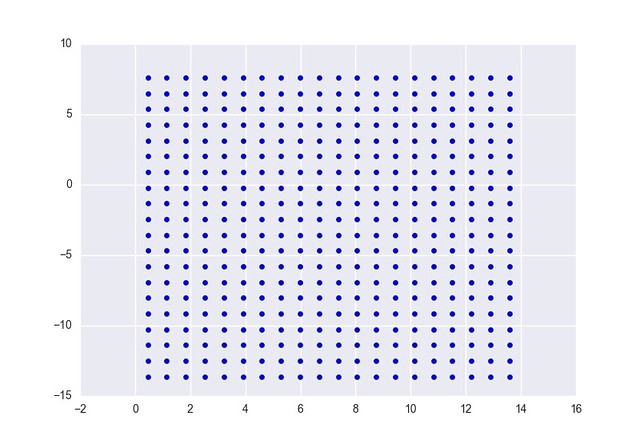
x01をプロットするとこうなります。
sns.plt.scatter(x01[:,0], x01[:,1])
分類する
学習自体は、scikit-learn提供のクラスに教師となるデータを与えてオブジェクト生成するだけなので、とても簡単。
from sklearn.cross_validation import train_test_split
from sklearn.metrics import accuracy_score
from sklearn.ensemble import RandomForestClassifier
# 分類にはランダムフォレストを使ってみる
model = RandomForestClassifier(n_estimators=100, random_state=0)
# 学習する
model.fit(X, y)
# 予測する
Z = model.predict(x01).reshape(x0.shape)
分類した結果を出力してみると… make_blobsに与えたcentersパラメータが目的変数として、見事に0-3の間で分類されてますね。
In[245]:Z
Out[245]:
array([[2, 2, 2, 2, 2, 2, 2, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3],
[2, 2, 2, 2, 2, 2, 2, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3],
[2, 2, 2, 2, 2, 2, 2, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3],
[2, 2, 2, 2, 2, 2, 2, 2, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3],
[2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3],
[2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3],
[2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3],
[2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3],
[2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 3, 2, 3, 3, 3, 3, 3, 3, 3, 3],
[2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 3, 2, 0, 0, 0, 0, 0, 0, 0, 0],
[2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 0, 0, 0, 0, 0, 0, 0, 0],
[2, 2, 2, 2, 2, 2, 2, 2, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[2, 2, 2, 2, 2, 2, 2, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[2, 2, 2, 2, 2, 2, 2, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[2, 2, 2, 2, 2, 2, 2, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 1, 0, 0],
[1, 1, 1, 1, 1, 1, 1, 1, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]])
make_blobsで作った教師データと予測結果を重ねて表示してみると、
sns.lmplot("X0", "X1", data=df, hue="target", fit_reg=False)
sns.plt.pcolormesh(x0, x1, Z, alpha=0.1, cmap="jet")
sns.plt.show()
こうなります。
まとめ
端的に言うと、見た目も大事。
見る人の興味を引くような美しさが、可視化したデータには必要なんだなと。
データサイエンスやマイニングを仕事にする人って、統計学やプログラミングの知識(他にもあるけど)だけでなく、こういった美的センスというか、ある意味芸術に近い領域の知識も必要そうと感じた次第です。
とりあえず美的センスは置いといて、データサイエンス勉強会で紹介してもらった統計お勧め本は読んでおかねば。アマゾンレビューでも評価が高いので、まずはこの辺りを立ち読みしてから攻めよう。


