TensorFlowを手持ちのMacにインストールしてチュートリアルを写経...する前に、まずは復習がてらscikit-learnのSVMを使って分類してみようと思います。
久々ですっかり忘れてきているもので。
MNIST手書き文字イメージデータのダウンロード
THE MNIST DATABASEからトレーニング用とテスト用の手書きイメージデータをダウンロードしましょう。
以下4つです。
- train-images-idx3-ubyte.gz: training set images (9912422 bytes)
- train-labels-idx1-ubyte.gz: training set labels (28881 bytes)
- t10k-images-idx3-ubyte.gz: test set images (1648877 bytes)
- t10k-labels-idx1-ubyte.gz: test set labels (4542 bytes)
手で落としてgunzipしてもいいんですが、せっかくなのでpythonで書いてみます。
MNIST手書きイメージデータを扱うためだけのクラス
ダウンロードしてgzip伸長する関数を書くと、こうなります。
…最初メモリを節約しようとgeneratorで書いたんですが、データ数が多すぎて処理が重くなったのでやめました^^;
代わりに、流行り?のasyncioを使います。
MNIST手書き文字イメージデータのDataFrame化
先ほどのクラスを使えば、手書き文字イメージデータをDataFrame化するのは簡単です。
[code lang=python]
from mnist_dl import MnistWrapper
m = MnistWrapper()
train = m.get_train()
test = m.get_test()
images = test[0]
labels = test[1]
[/code]
このようにすれば、imagesとlabelsはすでにpandas.DataFrame化されています。楽ちん。
念のためデータの内容を確認すると、こんな感じです。
[code lang=python]
In [201]: images.shape
Out[201]: (10000, 784)
In [18]: images.loc[0].values.reshape(28, 28)
Out[18]:
array([[ 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0],
[ 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0],
[ 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0],
[ 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0],
[ 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0],
[ 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0],
[ 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0],
[ 0, 0, 0, 0, 0, 0, 84, 185, 159, 151, 60, 36, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0],
[ 0, 0, 0, 0, 0, 0, 222, 254, 254, 254, 254, 241, 198,
198, 198, 198, 198, 198, 198, 198, 170, 52, 0, 0, 0, 0,
0, 0],
[ 0, 0, 0, 0, 0, 0, 67, 114, 72, 114, 163, 227, 254,
225, 254, 254, 254, 250, 229, 254, 254, 140, 0, 0, 0, 0,
0, 0],
[ 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 17, 66,
14, 67, 67, 67, 59, 21, 236, 254, 106, 0, 0, 0, 0,
0, 0],
[ 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 83, 253, 209, 18, 0, 0, 0, 0,
0, 0],
[ 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 22, 233, 255, 83, 0, 0, 0, 0, 0,
0, 0],
[ 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 129, 254, 238, 44, 0, 0, 0, 0, 0,
0, 0],
[ 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 59, 249, 254, 62, 0, 0, 0, 0, 0, 0,
0, 0],
[ 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 133, 254, 187, 5, 0, 0, 0, 0, 0, 0,
0, 0],
[ 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 9, 205, 248, 58, 0, 0, 0, 0, 0, 0, 0,
0, 0],
[ 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 126, 254, 182, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0],
[ 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 75, 251, 240, 57, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0],
[ 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
19, 221, 254, 166, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0],
[ 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 3,
203, 254, 219, 35, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0],
[ 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 38,
254, 254, 77, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0],
[ 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 31, 224,
254, 115, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0],
[ 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 133, 254,
254, 52, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0],
[ 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 61, 242, 254,
254, 52, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0],
[ 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 121, 254, 254,
219, 40, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0],
[ 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 121, 254, 207,
18, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0],
[ 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0]])
[/code]
画像ファイルとして書き出すこともできます。
[code lang=python]
import matplotlib.pyplot as plt
plt.imsave("five.png", images.loc[0].values.reshape(28, 28))
[/code]
小さ。

SVM(Support Vector Machine)を使った分類
あとはSVMで分類するだけ。…と言っても、手持ちのMacでは性能が低くて、数時間かけても処理が終わらない…。
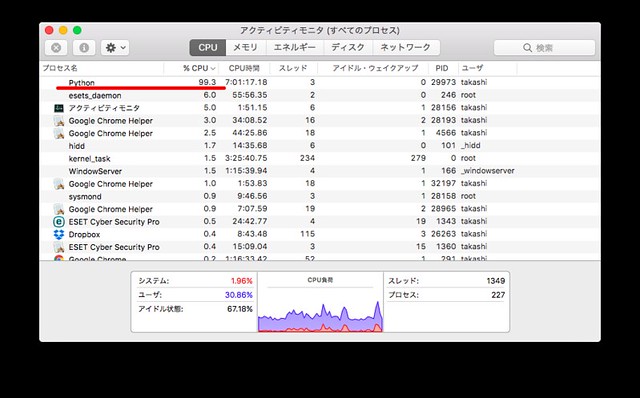
ので、データ量を1/10に絞ってあります。
[code lang=python]
from sklearn import svm
svc = svm.SVC()
# 学習
fit = svc.fit(train[0].loc[:6000].values, train[1].loc[:6000].values)
# 予測
predicted = svc.predict(test[0].values)
[/code]
惨敗の正答率
サンプル数を削りすぎたのか…? パラメータを振るなり色々試してみないと分かりませんが、とにかく酷い結果…。
正答率は2割未満。
[code lang=python]
for i in range(0, 1000, 100):
print("{}-{}: {:.2f}".format(i, i+100, metrics.accuracy_score(svc.predict(test[0].loc[i : i+100].values), test[1].loc[i : i+100].values)))
0-100: 0.14
100-200: 0.14
200-300: 0.13
300-400: 0.16
400-500: 0.10
500-600: 0.06
600-700: 0.12
700-800: 0.15
800-900: 0.12
900-1000: 0.16
[/code]
そもそも何かを根本的に間違えたか?と、念のため学習用のデータで試した結果がこちら。
[code lang=python]
for i in range(5900, 6500, 100):
print("{}-{}: {:.2f}".format(i, i+100, metrics.accuracy_score(svc.predict(_train.images.loc[i : i+100].values), _train.labels.loc[i : i+100].values)))
5900-6000: 1.00
6000-6100: 0.12
6100-6200: 0.13
6200-6300: 0.11
6300-6400: 0.12
6400-6500: 0.11
[/code]
学習用データを1/10に削った境目で、綺麗に正答率が激減してますね…。
次回に続く。
