現職の会社がおかしくなり始めてから、大企業にありがちな上流工程に特化していくことに危機感を感じたこともあり、リツアンSTCさんとコンタクトを取り始めたんですが、まだ入社したわけでもないのにBizjapanさん主催の勉強会に誘っていただきました。
開催日2/13(土)の前日夜でしたが…Σ(・□・;)
ただ、その概要を見ると、これは受講しないと勿体なすぎると感じたので、嫁さんに無理を言って行きました。勉強会後の打ち上げが本番という定説がありますが、今回はさすがに参加せず…。
コモディティ化しがちな製品群よりも、データの加工、分析、可視化技術はそうそう簡単に廃れないのかなと。一部、現職の製品でも活用していた気がするけど。
以下、DoorKeeperに掲載されている概要です。
概要
今回公開するレクチャーは、Bizjapanの理系大学院生により、文系の学生が大半を占めるBizjapanメンバーにデータサイエンスを導入するために作成し使用しているものです。内容的には、データサイエンス概略、機械学習概略、データ解析を行うためのツール比較(Excel、R、Python) 、Excelのヘルプの使い方、Excelによるデータの視覚化、線形回帰・曲線回帰とその最適な回帰式の選択方法、ソルバーでの最適化問題の解法、統計ソフトRの基本操作とRStudio、使用するデータについての解説、Rでのデータ操作、help関数の使い方とhelp画面の見方、CRANの見方、パッケージのインストール・実行方法、グラフィクスパッケージ、各種機械学習関数の使い方とformulaについて、機械学習のパッケージを用いた機械学習例、データの読み込みと書き出し、を予定しています。
統計学をちゃんと学んでいない身としては、色々とガクブルな用語が出てきます…。
でも、Rの基本操作以降はPythonやRubyをある程度以上触ったことがあれば、意外とついて行けました。
とは言え、R組み込み関数のhelpに表示される機能や実装概要を読んでもサッパリ理解できませんけど…。
イベント趣旨
これもDoorKeeperに掲載されています。
・データサイエンス・機械学習の概要を理解する。
・Excel, Rでのデータの可視化と機械学習をできるようにする。
・CRANの各種パッケージを利用できるようにする。
開始時刻には遅れてしまったので、概要は聞けませんでした。
ExcelはOSXにインストール済みだったのが2011版な上、サービスパックをインストールしてなくてリゾルバーなどのツールが入っておらず、全くついていけませんでした。というより、サンプルデータも持ってなかったので、ただ聞いてるだけになってしまった…。
Rでのデータ可視化以降は、とても楽しいひと時でした。
今回は機械学習までは進みませんでしたが、RStudioの使い方、CRANの見所を教えてもらえたので、サンプルを試しながらRに触れて慣れることはできそうです。
具体的には以下のような内容でした。
- RStudioコンソールで
data()を実行すると、R/RStudioに標準で用意されたサンプルデータを参照できるAirPassengers Monthly Airline Passenger Numbers 1949-1960 BJsales Sales Data with Leading Indicator BJsales.lead (BJsales) Sales Data with Leading Indicator BOD Biochemical Oxygen Demand CO2 Carbon Dioxide Uptake in Grass Plants - 同様に、
help(CO2)を実行すると、そのデータに関する詳細説明を参照できるCO2 {datasets} R Documentation Carbon Dioxide Uptake in Grass Plants Description The CO2 data frame has 84 rows and 5 columns of data from an experiment on the cold tolerance of the grass species Echinochloa crus-galli. ... Examples require(stats); require(graphics) coplot(uptake ~ conc | Plant, data = CO2, show.given = FALSE, type = "b") ## fit the data for the first plant fm1 <- nls(uptake ~ SSasymp(conc, Asym, lrc, c0), data = CO2, subset = Plant == "Qn1") summary(fm1) ## fit each plant separately fmlist <- list() for (pp in levels(CO2$Plant)) { fmlist[[pp]] <- nls(uptake ~ SSasymp(conc, Asym, lrc, c0), data = CO2, subset = Plant == pp) } ## check the coefficients by plant print(sapply(fmlist, coef), digits = 3) - データのhelpの最後の方にあるExampleに書かれたサンプルコードを実行すると、そのデータをどう加工し分析すべきか、大体分かる
上記のCO2データだと結果をprintするだけなので面白みが少ないんですが、help(heatmap)のサンプルを試すと面白いです。
require(graphics); require(grDevices)
x <- as.matrix(mtcars)
rc <- rainbow(nrow(x), start = 0, end = .3)
cc <- rainbow(ncol(x), start = 0, end = .3)
hv <- heatmap(x, col = cm.colors(256), scale = "column",
RowSideColors = rc, ColSideColors = cc, margins = c(5,10),
xlab = "specification variables", ylab = "Car Models",
main = "heatmap(<Mtcars data>, ..., scale = ?"column?")")
utils::str(hv) # the two re-ordering index vectors
## no column dendrogram (nor reordering) at all:
heatmap(x, Colv = NA, col = cm.colors(256), scale = "column",
RowSideColors = rc, margins = c(5,10),
xlab = "specification variables", ylab = "Car Models",
main = "heatmap(<Mtcars data>, ..., scale = ?"column?")")
## "no nothing"
heatmap(x, Rowv = NA, Colv = NA, scale = "column",
main = "heatmap(*, NA, NA) ~= image(t(x))")
round(Ca <- cor(attitude), 2)
symnum(Ca) # simple graphic
heatmap(Ca, symm = TRUE, margins = c(6,6)) # with reorder()
heatmap(Ca, Rowv = FALSE, symm = TRUE, margins = c(6,6)) # _NO_ reorder()
## slightly artificial with color bar, without and with ordering:
cc <- rainbow(nrow(Ca))
heatmap(Ca, Rowv = FALSE, symm = TRUE, RowSideColors = cc, ColSideColors = cc,
margins = c(6,6))
heatmap(Ca, symm = TRUE, RowSideColors = cc, ColSideColors = cc,
margins = c(6,6))
## For variable clustering, rather use distance based on cor():
symnum( cU <- cor(USJudgeRatings) )
hU <- heatmap(cU, Rowv = FALSE, symm = TRUE, col = topo.colors(16),
distfun = function(c) as.dist(1 - c), keep.dendro = TRUE)
## The Correlation matrix with same reordering:
round(100 * cU[hU[[1]], hU[[2]]])
## The column dendrogram:
utils::str(hU$Colv)
上記サンプルをRStudioで実行すると、以下のような結果が得られます。
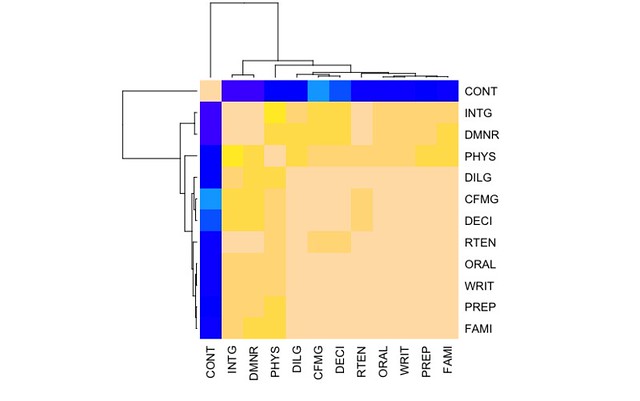
似たような傾向のデータをソートした上で可視化しているので、マップ画像を見るとその傾向が見て取れると思います。
まとめ
世の中ではこういう分析が行われているのか…と、興奮と危機感が入り混じった気持ちになりました。
次回の開催日は未定っぽいですが、今後も参加して理解を深めたい内容でした。
また、これほどサンプルコードやサンプルデータが充実したhelpは他にないと感じました。Rだけでなく、Pythonでデータ解析の勉強をする際にも活用できそうです。
そんなわけで、途中で止まっていたこの本を再開しようかなと。
